III - Applications¶
Summary
On this page, we apply the results of the previous page to formulate approaches for solving pre-learning and post-learning problems.
Specifically, in section 1 - Achievable Performance we provide an approach for quantifying the best performance, including \(R^2\) and classification accuracy, that can be extracted out of a specific set of inputs in a regression or classification problem, irrespective of the model used.
Additionally, in section 2 - Variable Selection Analysis we introduce a model-free variable selection analysis providing the best \(i\) inputs to use in a set of \(d\) inputs, for \(i\) varying from \(1\) to \(d\), as well as the corresponding best performance (\(R^2\) and classification accuracy) that can be achieved by any model using these \(i\) inputs.
In section 3 - Model Improvability we discuss quantifying the extent to which a trained supervised learning model can be improved without resorting to additional datasets.
Finally, in section 4 - Model Audit we discuss how to shed some light on the workings of so-called black-box models, and how detect bias in trained supervised learning models.
Throughout this page, we consider the supervised learning problem consisting of predicting label \(y\) (categorical for classification problems, and continuous for regression problems) using inputs \(x = (x_1, \dots, x_d)\). Each input \(x_i\) can be either continuous or categorical. All entropies and mutual informations are assumed to be known. We discuss model-free maximum entropy estimation of entropies and mutual informations on the next page.
1 - Achievable Performance¶
a) Achievable-\(R^2\)¶
In a regression model \(y=f(x) + \epsilon\) denoted \(\mathcal{M}\), the \(R^2\) is defined as the fraction of variance of the output \(y\) that is explained by the regression model:
The term \(\frac{\mathbb{V}\text{ar}\left(y \vert f(x)\right)}{\mathbb{V}\text{ar}(y)}\) represents the fraction of variance of the label that cannot be explained using inputs, under our model.
Although variance is as good a measure of uncertainty as it gets for Gaussian distributions, it is a weak measure of uncertainty for other distributions, unlike the entropy. Considering that the entropy (in nats) has the same unit/scale as the (natural) logarithm of the standard deviation, we generalize the \(R^2\) as follows:
Note that when \((y, f(x))\) is jointly Gaussian (e.g. Gaussian Process regression, including linear regression, with Gaussian additive noise), the generalized \(R^2\) above is identical to the original \(R^2\).
This generalized \(R^2\) applies to both regression and classification problems, linear or nonlinear. Indeed, classification models similarly involve learning a function \(f\) representing one or multiple separating surfaces, such that the predictive distribution over all possible labels generated by our model takes the form \(y|f(x)=*\). In logistic or probit regression for instance, \(f(x) = \omega^Tx\).
Important
Data Processing Inequality (DPI): For any function \(f\), for any random variables \(x\) and \(y\), \(I(x; y) \geq I(f(x); y)\). Moreover, the equality holds when either \(f\) is invertible or \(x\) and \(y\) are independent conditional on \(f(x)\), \(x \perp y ~\vert~ f(x)\). [*]
It follows from the data processing inequaliy that the maximum \(R^2\) a supervised learning model can achieve is \(\bar{R}^2(x) = 1 - e^{-2I\left(y; x\right)}\). This upper bound is achieved when \(x \perp y ~\vert~ f(x)\) or, in plain english, when \(f(x)\) carries all the information about \(y\) that there is in \(x\).
Definition
For any supervised learning model \(\mathcal{M}\),
We refer to \(\bar{R}^2(x)\) as the achievable- \(R^2\) using inputs \(x\).
Note
The achievable-\(R^2\) places a hard bound on the performance that can be achieved by any supervised learning model, no matter how deep or fancy. It is solely a function of the mutual information between inputs used and the label \(I\left(y; x\right)\), which quantifies how informative inputs are collectively about the label.
As expected, when inputs are not informative about the label, no model, no matter how fancy, can predict the label. The reverse is also true. There exists a regression model using \(x\) to predict \(y\) whose \(R^2\) is \(\bar{R}^2\). [†]
All we need to estimate the achievable-\(R^2\) is an estimator for the mutual information \(I\left(y; x\right)\), which we will provide on the following page.
b) Achievable True Log-Likelihood¶
The log-likelihood per sample of a supervised learning model \(\mathcal{M}\) predicting label \(y\) from inputs \(x\) with predictive pdf \(p_\mathcal{M}(y|f(x))\) is defined for \(n\) i.i.d. samples \((y_1, x_1), \dots, (y_n, x_n)\) as
Its population version \(\mathcal{LL}\left(\mathcal{M}\right)\), which we call the true log-likelihood per sample, is obtained by taking the expectation with respect to the true data generating distribution, and we have
where \(p(y | f(x))\) is the true conditional pdf, the first inequality stems from Gibbs’ inequality and the second inequality results from applying the DPI.
Definition
For any supervised learning model \(\mathcal{M}\), the true log-likelihood per sample satisfies
We refer to \(\bar{\mathcal{LL}}\) as the achievable true log-likelihood per sample using inputs \(x\).
Note
The achievable true log-likelihood per sample places a hard bound on the true log-likelihood per sample that can be achieved by any supervised learning model, no matter how deep or fancy.
It is solely a function of the mutual information between inputs used and the label \(I\left(y; x\right)\), which quantifies how informative inputs are collectively about the label, and the entropy of the \(h(y)\), which reflects the true log-likelihood per sample of the naive strategy consisting of always predicting the mode of the distribution of \(y\).
As expected, when inputs are not informative about the label, no model, no matter how fancy, can outperform the naive strategy. The reverse is also true. Indeed, when the model’s predictive pdf \(p_\mathcal{M}(y|f(x))\) is the true predictive pdf \(p(y|f(x))\), and \(y \perp x | f(x)\) (i.e. \(f(x)\) contains all the information about \(y\) that is in \(x\)), the inequality is an equality.
c) Achievable Classification Accuracy¶
Entropy And Classification Accuracy¶
First, we want to calculate the best accuracy that can be achieved by predicting an outcome of a discrete distribution taking \(q\) distinct values, and that has entropy \(h(\mathbb{P})\).
We denote \(\pi_1, \dots, \pi_q\) the probability masses sorted in decreasing order. Faced with predicting an outcome of \(\mathbb{P}\), the best strategy is to always predict the most likely outcome. This strategy has accuracy (a.k.a. probability of being correct) \(\mathcal{A}(\mathbb{P}) := \underset{i \in [1..q]}{\max} \pi_i = \pi_1\).
We note that, among all discrete distributions taking \(q\) distinct values and that have the same highest outcome probability \(\pi_1\), the one with the highest entropy is the one whose \((q-1)\) least likely outcomes have the same probability (i.e. the most ‘spread out’ distribution).
Indeed,
where \(\omega = \sum_{i=2}^q \pi_i\). The inequality above is a direct application of Jensen’s inequality to the (convex) the logarithm function, and the equality holds if and only if all \(\pi_i\) are the same for \(i \geq 2\) and equal to \(\frac{\omega}{q-1}\).
A corollary of the foregoing result is that, among all discrete distributions taking \(q\) distinct values and that have the same entropy, if there is one whose \((q-1)\) least likely outcomes have the same probability, then its highest outcome probability is the largest of them all.
We complement this result by showing that for any possible value \(h\) of the entropy of a discrete distribution taking \(q\) distinct values, there exists a discrete distribution whose entropy is \(h\) and whose \((q-1)\) least likely outcomes have the same probability.
All possible values for \(h\) lie in \([0, \log q]\). [‡] Let us denote \(\bar{h}_q(a)\) the entropy of a discrete distribution whose most likely outcome has probability \(a\), and whose \((q-1)\) least likely outcomes have the same probability:
A simple study of the function \(a \to \bar{h}_q(a)\) shows that it is differentiable, decreasing, concave, and invertible on \(\Big[\frac{1}{q}, 1\Big]\), and the image of \(\Big[\frac{1}{q}, 1\Big]\) is \([0, \log q]\); which is what we needed to show.
Putting everything together, for a given entropy \(h\) the best accuracy that can be achieved by predicting an outcome of any discrete distribution taking \(q\) distinct values, and that has entropy \(h\) is given by
where the function \(h \to \bar{h}_q^{-1}(h)\) is the inverse of the function \(a \to \bar{h}_q(a)\) and is easily evaluated numerically.
Important Equation
The figure below illustrates the bound for \(q\) ranging between \(2\) and \(100\).
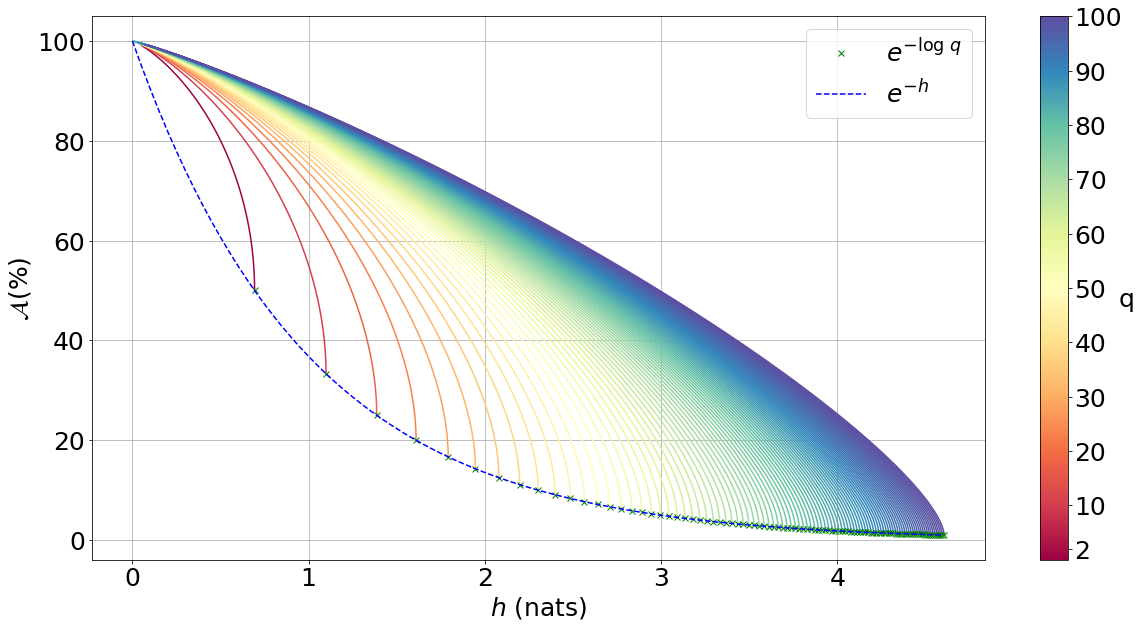
Fig 1. Accuracy achievable in predicting the outcome of a discrete distribution with q possible outcomes.¶
Conditional Entropy and Predictive Accuracy¶
We apply the result above to classification models. Faced with predicting \(y\) given a specific value of \(x=*\), the best prediction is the outcome
and it has accuracy \(\mathbb{P}(y=j | x=*)\), where \(y|x=*\) is the true data generating conditional distribution. Any other prediction \(i\) would, by definition of \(j\), have a lower accuracy \(\mathbb{P}(y=i | x=*)\).
The best possible overall accuracy a model can achieve is therefore
where the expectation is taken under the true data generating distribution of \(x\).
For a model to achieve maximum accuracy, all that is needed is for its most likely outcome to coincide with that of \(y|x=*\) for every value \(x=*\). Among all such models, there is the true data generating predictive distribution \(* \to y|x=*\), which is the maximum-accuracy model that has the lowest cross-entropy loss as discussed in the previous section.
Another maximum-accuracy model is the model whose predictive distribution has the same entropy as that of the previously mentioned model, namely \(h(y|x=*)\) and, of course, whose outcome with the highest probability is the same as that of \(y|x=*\). [§]
It follows from the previous analysis that its highest outcome probability is greater than or equal to the model accuracy (which is the highest outcome probability of the distribution \(y|x=*\) which has the same entropy),
with equality when the true data generating predictive distribution happens to make no distinction between the \((q-1)\) least likely outcomes. Additionally, it follows from the concavity of \(\bar{h}_q^{-1}\) that
where the second inequality is an equality when the entropy of the true data generating predictive distribution \(h(y|x=*)\) doesn’t vary much over the domain.
Definition
For any classification model \(\mathcal{M}\) using inputs \(x\) to predict label \(y\), and that has accuracy \(\mathcal{A}\left(\mathcal{M}\right)\), we have
We refer to \(\bar{\mathcal{A}}(x)\) as the achievable classification accuracy using inputs \(x\).
Note
The achievable classification accuracy places a hard bound on the accuracy that can be achieved by any classification model, no matter how deep or fancy. It is solely a function of the mutual information between inputs used and the label \(I\left(y; x\right)\), which quantifies how informative inputs are collectively about the label, and the entropy of the \(h(y)\), which reflects the accuracy of the naive strategy consisting of always predicting the most frequent outcome \(j = \underset{i \in [1..q]}{\operatorname{argmax}} \mathbb{P}(y=i)\).
As expected, when inputs are not informative about the label, no model, no matter how fancy, can outperform the naive strategy. The reverse is true when inputs are chosen so that for every value \(x=*\) the true data generating conditional distribution \(y|x=*\) places the same probability mass on all \((q-1)\) least likely outcome (i.e. there is no clear second-best), and when the true predictive entropies \(h(y|x=*)\) are the same across the domain (i.e. inputs are not much more informative about the label in certain regions of the domain than others).
d) Regression Achievable-RMSE¶
In a regression model \(y=f(x) + \epsilon\) denoted \(\mathcal{M}\), the Root Mean Squared Error (RMSE) is defined as the square root of the mean of the squared error:
Following the same reasoning as for the achievable-\(R^2\), we generalize the ratio \(\frac{\mathbb{V}\text{ar}\left(y \vert f(x)\right)}{\mathbb{V}\text{ar}\left(y\right)}\) by replacing it by \(e^{-2I\left(y; f(x)\right)}\). We obtain
Note that when \((y, f(x))\) is jointly Gaussian (e.g. Gaussian Process regression, including linear regression with Gaussian additive noise), the generalized RMSE above is identical to the original RMSE. It follows from the data processing inequaliy that the smallest RMSE any regression model can achieve is \(\bar{RMSE}(x) = e^{-I\left(y; x\right)} \sqrt{\mathbb{V}\text{ar}\left(y\right)}\). This lower bound is reachable (for example when \(f(x)=E(y|x)\)).
Definition
For any regression model \(\mathcal{M}\),
We refer to \(\bar{RMSE}(x)\) as the achievable-RMSE using inputs \(x\).
Note
The achievable-RMSE places a hard bound on the performance that can be achieved by any regression model, no matter how deep or fancy. It is solely a function of the mutual information between inputs used and the label \(I\left(y; x\right)\), which quantifies how informative inputs are collectively about the label, and the output standard deviation, which is the RMSE of the naive strategy consisting of always predicting \(E(y)\).
As expected, when inputs are not informative about the label, no model, no matter how fancy, can do better than the naive benchmark consisting of always predicting the mean output \(f(x) = E(y)\).
All we need to estimate the achievable-RMSE is an estimator for the mutual information \(I\left(y; x\right)\), which we will provide on the following page.
2 - Variable Selection Analysis¶
We consider a supervised learning problem consisting of predicting label \(y\). There are \(d\) candidate inputs or variables, namely \(x = (x_1, \dots, x_d)\), that we could use to do so, and our aim is to quantify the maximum value every one of them could bring to the table.
We proceed in two steps components. First, we analyze the value that can be generated by using each candidate input \(x_i\) in isolation to predict our label \(y\).
a) Univariate Variable Importance¶
By applying the results of the section 1 - Achievable Performance to each input in isolation, we are able to compute the highest performance or lowest loss that can be achieved by using each input in isolation.
Univariate Achievable-\(R^2\): The highest \(R^2\) that can be achieved by any model solely using input \(x_i\) is given by
Important Equation
Univariate Achievable-RMSE: The smallest RMSE that can be achieved by any model solely using input \(x_i\) is given by
Important Equation
Univariate Achievable True Log-Likelihood Per Sample: The highest true log-likelihood per sample that can be achieved by any supervised learning model solely using \(x_i\) is given by
Important Equation
Univariate Achievable Classification Accuracy: For classification problems, the highest accuracy that can be achieved by any classification model solely using input \(x_i\) is given by
Important Equation
b) Marginal Variable Importance¶
The univariable variable importance analysis above does not paint the full picture.
Some inputs/variables might be redundant. Redundant variables could cause model training to be less robust, for instance because of ill-conditioning. Redundant variables could also artificially increase model complexity, for instance when it is directly related to the number of inputs/variables, without increasing the effective number of variables. This could result in overfitting, longer model training times, and a waste of computating resources. Finally, when datasets are acquired, redundant datasets are a waste of money.
Complementary inputs/variables are the flip side of redundant inputs. They provide the highest marginal value added, make model training more robust, yield an efficient number of variables and mitigate overfitting and computing resource waste, and overall generate a high ROIs.
As previously discussed, whether we use the \(R^2\), the classification cross-entropy loss, or the classification accuracy, the overall value that can be generated by using all inputs \(x = (x_1, \dots, x_d)\) collectively to predict \(y\), is a function of the mutual information \(I(y; x)\).
Selection Order¶
For every permutation \(\{\pi_1, \dots, \pi_d\}\) of \(\{1, \dots, d\}\) we have
\(I\left(y; x_{\pi_1}\right)\) reflects the maximum value that variable \(x_{\pi_1}\) can bring to the supervised learning problem, whereas \(I\left(y; x_{\pi_i} | x_{\pi_{i-1}}, \dots, x_{\pi_1}\right)\) reflects the maximum marginal or incremental value that variable \(x_{\pi_i}\) can bring over the variables \(x_{\pi_{i-1}}, \dots, x_{\pi_1}\).
To rank variables by decreasing order of marginal value added, we proceed as follows:
The first input/variable selected is the one with the highest mutual information with the label, or said differently, the input that is the most valuable when used in isolation to predict the label:
Important Equation
The \((i+1)\)-th input/variable selected is the one, among all remaining \(d-i\) inputs that haven’t yet been selected, that has the highest mutual information with the label conditional on all inputs previously selected, or said differently, the input that complements the \(i\) previous selected inputs the most:
Important Equation
Maximum Marginal \(R^2\) Increase¶
The maximum contribution of \(\pi_1\) to the achievable-\(R^2\) is simply \(\bar{R}^2(x_{\pi_1})\).
The maximum contribution of \(\pi_{i+1}\) to the achievable-\(R^2\) is the difference between the achievable-\(R^2\) using the first \((i+1)\) inputs selected and the achievable-\(R^2\) using the first \(i\) inputs selected. It reads:
Important Equation
Note that, as expected, the achievable-\(R^2\) can never decrease as a result of adding an input. Additionally, it would only increase if the conditional mutual information \(I\left(y; x_{\pi_{i+1}} | x_{\pi_1}, \dots, x_{\pi_i}\right)\) is strictly positive, meaning \(x_{\pi_{i+1}}\) is not redundant in light of \(x_{\pi_1}, \dots, x_{\pi_i}\). The higher the conditional mutual information the more complementary value the new input is expected to add.
Maximum Marginal RMSE Decrease¶
Following the same reasoning as for the \(R^2\), we obtain
Important Equation
Maximum Marginal True Log-Likelihood Per Sample Increase¶
The maximum contribution of \(\pi_1\) to the achievable true log-likelihood per sample is simply \(\bar{LL}(x_{\pi_1})\).
The maximum contribution of \(\pi_{i+1}\) to the achievable true log-likelihood per sample is the difference between the achievable true log-likelihood per sample using the first \((i+1)\) inputs selected and the achievable true log-likelihood per sample using the first \(i\) inputs selected. It reads:
Important Equation
Once again, as expected, the achievable true log-likelihood per sample never decreases as a result of adding an input. Additionally, it would only increase if the conditional mutual information \(I\left(y; x_{\pi_{i+1}} | x_{\pi_1}, \dots, x_{\pi_i}\right)\) is strictly positive, meaning \(x_{\pi_{i+1}}\) is not redundant in light of \(x_{\pi_1}, \dots, x_{\pi_i}\). The higher the conditional mutual information the more complementary value the new input is expected to add.
Maximum Marginal Classification Accuracy Increase¶
The same logic can be used to calculate the maximum contribution of any input to achievable classification accuracy using \(\bar{\mathcal{A}}(x)\). We will not discuss this any further as the interpretation is not as straightforward as for the previous two metrics.
3 - Model Improvability¶
Once a model has been learned, it is important to get a sense for whether it could be improved without resorting to additional inputs, and if so, to what extent.
a) Suboptimality¶
Absolute Suboptimality¶
Let us consider a model \(\mathcal{M}\) predicting that the label \(y\) associated to \(x\) is \(f(x)\). As previously discussed, \(I\left(f(x); y\right)\) reflects how accurate \(\mathcal{M}\) is, and, by the data processing inequality, the highest possible value for \(I\left(f(x); y\right)\) is \(I\left(x; y\right)\). Thus,
Important Equation
is a natural measure of how suboptimal \(\mathcal{M}\) is. Note that, using \(SO\), \(\mathcal{M}\) is optimal if and only if \(x\) and \(y\) are statistically independent conditional on \(f(x)\), meaning that \(f(x)\) fully captures everything there is in \(y\) about \(x\), and as such \(\mathcal{M}\) cannot be improved.
Note
In regression problems, it is worth noting that, because \(SO(\mathcal{M})=0\) (or equivalently because \(x\) and \(y\) are statistically independent conditional on \(f(x)\)) doesn’t necessarily mean that \(\mathcal{M}\) is the most accurate regression model using \(x\) to predict \(y\) there can be.
It means that the most accurate model there is can be derived from \(f(x)\). In other words, the regression model didn’t lose any of the information in \(x\) pertaining to \(y\), and we are a univariate regression away from the most accurate model.
Additive Suboptimality¶
As previously discussed, \(SO\) is a weak optimality criteria for regression problems in that an \(SO\)-optimal model needs not be the most accurate.
To address this limitation, we consider the following additive regression model
As long as \(\epsilon_1\) can be predicted using \(x\), the regression model above can be improved by solving the regression problem \(\epsilon_1 = f_2(x) + \epsilon_2\). More generally, so long as \(\epsilon_{k-1}\) can be predicted using \(x\), by solving the regression problem \(\epsilon_{k-1} = f_k(x) + \epsilon_k\), the regression model
will outperform the previous regression model \(y = \sum_{i=1}^{k-1} f_i(x) + \epsilon_{k-1}\), which itself outperforms the original regression model.
Along this line, we introduce the additive suboptimality score
Important Equation
We note that
Hence,
Note
Additive suboptimality enforces two requirements. Through \(SO(\mathcal{M})\), it requires the model to capture in \(f(x)\) as much of the information about \(y\) that is in \(x\) as possible. Through \(I(y-f(x); f(x))\) it requires residuals to be as independent as possible from predictions or, said differently, it requires the model to be accurate or at least hard to improve in an additive fashion.
Reducing \(ASO\) to zero ensures that, not only can we no longer improve our regression model additively, but we have exploited all the insights in \(x\) about \(y\).
b) Lost Performance¶
Once more, let us consider a model \(\mathcal{M}\) predicting that the label \(y\) associated to \(x\) is \(f(x)\). Lost performance is the flip side of achievable performance.
Essentially, what could be achieved in predicting \(y\) with \(x\) minus what could be achieved in predicting \(y\) with our trained model’s prediction \(f(x)\) constitutes what has been lost by our model when turning \(x\) into \(f(x)\).
Lost \(R^2\)¶
The highest \(R^2\) that can be achieved in predicting \(y\) with \(x\) is the achievable-\(R^2\) \(\bar{R}^2(x) = 1-e^{-2I(y;x)}\), and the highest \(R^2\) that can be achieved in predicting \(y\) with \(f(x)\) is \(R^2(\mathcal{M}) = 1-e^{-2I(y;f(x))}\).
Taking the difference, we get the lost \(R^2\):
Important Equation
As expected, the suboptimality score SO plays a key role in the amount of \(R^2\) lost. Specifically, there is always \(R^2\) lost, unless the trained model is optimal (i.e. \(SO(\mathcal{M}) = 0\)).
The more suboptimal the trained model is, the more \(R^2\) was lost by the model.
Excess RMSE¶
The smallest RMSE that can be achieved in predicting \(y\) with \(x\) is the achievable-RMSE \(\bar{RMSE}(x) = e^{-I(y;x)}\sqrt{\mathbb{V}\text{ar}\left(y\right)}\), and the smallest RMSE that can be achieved by predicting \(y\) with \(f(x)\) is \(RMSE(\mathcal{M}) = e^{-I\left(y;f(x)\right)}\sqrt{\mathbb{V}\text{ar}\left(y\right)}\).
Taking the difference, we get the Excess RMSE:
Important Equation
Lost True Log-Likelihood Per Sample¶
The highest true log-likelihood per sample that can be achieved in predicting \(y\) with \(x\) is \(\bar{\mathcal{LL}}(x) = I(y; x)-h(y)\), and the highest true log-likelihood per sample that can be achieved in predicting \(y\) with \(f(x)\) is \(\mathcal{LL}(\mathcal{M}) = I(y; f(x))-h(y)\).
Taking the difference, we get that the true log-likelihood per sample lost is simply the suboptimality score.
Important Equation
Once more, as expected, the suboptimality score SO plays a key role in the amount of true log-likelihood per sample lost. Specifically, some true log-likelihood per sample is always lost, unless the trained model is optimal (i.e. \(SO(\mathcal{M}) = 0\)). The more suboptimal the trained model is, the more log-likelihood per sample the model would not have captured that it could.
Lost Classification Accuracy¶
Extension of the analysis above to classification accuracy is trivial. The best accuracy that can be achieved in predicting \(y\) with \(x\) is \(\bar{\mathcal{A}}(x) = \bar{h}_q^{-1}\left( h(y)-I(y; x)\right)\), and the accuracy achieved by model \(\mathcal{M}\) does not exceed \(\mathcal{A}(\mathcal{M}) = \bar{h}_q^{-1}\left( h(y)-I(y; f(x))\right)\).
Thus the accuracy loss by model \(\mathcal{M}\) is at least
Important Equation
c) Regression Residual Performance¶
For regression problems, we define residual performance as the maximum performance that can be achieved when trying to predict regression residuals with the same inputs. A high residual performance is an indication that the model can be improved additively (i.e. by focusing on predicting its residuals).
Residual \(R^2\)¶
The residual \(R^2\) reads
Important Equation
Residual RMSE¶
The residual RMSE reads
Important Equation
Residual Log-Likelihood¶
Similarly, the residual true log-likelihood per sample reads
Important Equation
Note that \(h\left(y-f(x) \right)\) is the log-likelihood per sample of the naive strategy consisting of predicting the mode of true unconditional residual distribution.
4 - Model Audit¶
As usual, we consider a model \(\mathcal{M}\) predicting that the label \(y\) associated to \(x\) is \(f(x)\).
a) Model Explanation¶
The natural inclination for studying a trained supervised learning model, especially regression models, is to mathematically study the function \(x \to f(x)\), for instance by evaluating its gradient, Hessian or its integral over all but one input/variable.
Not only is this approach tedious, but it does not apply all models. For instance, some inputs might be categorical in regression models, or in classification models \(f(x)\) would represent the categorical predicted label, and in both cases there is no smooth surface to take the gradient or hessian of. Even when the function \(x \to f(x)\) defines a smooth surface, it might not be available analytically (e.g. Gaussian process models). Even when it is available analytically, some mathematical operations could be analytically intractable and numerically impractical (e.g. computing large dimensional integrals to gauge marginal effects).
We resort to an information-theoretical alternative approach that is very flexible and yet requires nothing but the ability to evaluate the trained model at any input \(x\), and applies to both categorical and continuous inputs, classification and regression problems, smooth or otherwise.
Specifically, while quantifying the suboptimality of \(\mathcal{M}\) boils down to studying the structures in the distribution \((y, f(x))\), explaining the model \(\mathcal{M}\) could be done by studying the structures in the distribution \((x, f(x))\). Critically though, unlike in the suboptimality analysis, we are only interested in understanding how the model arrives at its decisions, and what decisions it would make in certain scenarios. We are not interested in dissecting model accuracy; this is done in the suboptimality analysis. Thus, our analysis has no bearing on the true data generating distribution of \(y\).
If we define \(y_p := f(x)\) then we may reuse the variable selection analysis of section 2 - Variable Selection Analysis to quantify the influence each input/variable \(x_i\) has on the model \(\mathcal{M}\), replacing \(y\) by \(y_p\). As for what distribution to use for inputs \(x\), the flexibility of this approach lies in the fact that it all depends on the scenario in which we want to make sense of our model’s decisions.
To make sense of our model decisions by focusing on inputs that are likely to arise in real life, we would choose as distribution for \(x\) the true data generating distribution (i.e. get samples of \(x\) from real-life observations, and generate corresponding samples of \(y_p\) by running our model on collected inputs). In general, however, we need not rely on, or be constrained by, the true data generating distribution.
Stress tests and scenario analyses are easily performed by choosing as distribution for \(x\) one that reflects the conditions of scenario. Whether it is fixing the values of certain categorical inputs, or requiring certain continuous inputs to take values in specific intervals (e.g. extreme values), all these scenarios can be expressed as distributions of \(x\), often times uniform on some domain, which we can generate i.i.d. samples from.
Performing our variable selection analysis will then inform us on the influence each input/variable has on the model decisions in the specific scenario of interest, either in isolation or in conjunction with other variables.
b) Quantifying Bias in Models¶
The ability to spot biases in trained machine learning models is increasingly important, as society becomes more and more AI-powered.
Detecting Bias¶
Detecting bias could be done by determining whether the category variable \(z\), upon which bias or discrimination could be based (e.g. race, gender, income level, etc.), has any implicit bearing on decision making, or decision making is oblivious to it.
As usual, this could be done by computing the mutual information between model predictions \(y_p=f(x)\) and \(z\) under the true data generating distribution
Important Equation
For \(z\) to have no bearing on \(\mathcal{M}\), or for \(\mathcal{M}\) to be oblivious to \(z\), \(Bias(\mathcal{M}; z)\) should be as close to \(0\) as possible.
Bias Source¶
Often times, models will not directly make use of the category variable \(z\), for legal or ethical reasons. In such an instance, to fix the bias, it is important to understand which inputs implicitly induced it. This could be done by comparing the overall impact of each input \(x_i\) on the decision \(y_p\) to its impact on \(y_p\) for a specific group \(z=j\). Assuming \(z\) can take up to \(q\) distinct values, we introduce the \(d \times q\) bias-source matrix
Important Equation
If \(BiasSource(\mathcal{M}; z)[i, j]\) is not close to \(0\), the data scientist should ask herself whether it is fair or ethical to treat individuals in group \(j\) differently from another individual with the same input characteristic \(x_i\) but in another group.
If the answer is no, then chances are that the empirical distribution \((x_i, y) | z=j\), as per the training dataset, was not representative of the true data generating distribution \((x_i, y)\), in which case the data scientist should consider collecting additional samples from group \(j\).
References
Footnotes
- *
Hint: The data processing inequality is well documented for categorical distributions. See for instance, Theorem 2.8.1 in [1] and its corollary. For continuous and mixed distributions, use the Definition (8.54) in [1], apply the data processing inequality to the quantized distributions, and take the supremum.
- †
To see why, let’s consider the most general form of regression models, given by the graphical model \(x \to z\). The random variable \(z\) is the prediction of \(y\) we form after observing \(x\). Such a model has \(R^2\) equal to \(1 - e^{-2I\left(y; z\right)}\) as discussed above. When \(z\) has the same distribution as the true data generating conditional distribution \(y|x\), our model achieves maximum \(R^2\).
- ‡
The uniform distribution is maximum entropy and has entropy \(\log q\), the entropy of a distribution with only one outcome with non-null probability is \(0\), and Shannon’s entropy is non-negative.
- §
As previously proved, for any entropy \(h\) we can always find a distribution whose \((q-1)\) least likely outcomes always have the same probability.
- ¶
True in the sense that \((y, x)\) is the true data generating distribution.